Optimization
Hype provides a highly configurable and modular gradient-based optimization functionality. This works similar to many other machine learning libraries.
Here's the novelty:
Thanks to nested AD, gradient-based optimization can be combined with any code, including code which internally takes derivatives of a function to produce its output. In other words, you can optimize the value of a function that is internally optimizing another function, or using derivatives for any other purpose (e.g. running particle simulations, adaptive control), up to any level.
In such a compositional optimization setting, all arising higher-order derivatives are handled for you through nested instantiations of forward and/or reverse AD. In any case, you only need to write your algorithms as usual, only implementing a regular forward algorithm.
Let's explain this through a basic example from the article "Jeffrey Mark Siskind and Barak A. Pearlmutter. Nesting forward-mode AD in a functional framework. Higher Order and Symbolic Computation 21(4):361-76, 2008. doi:10.1007/s10990-008-9037-1", where a parameter of a physics simulation using the gradient of an electric potential is optimized with Newton's method using the Hessian of an error, requiring third-order nesting of derivatives.
Optimizing a physics simulation
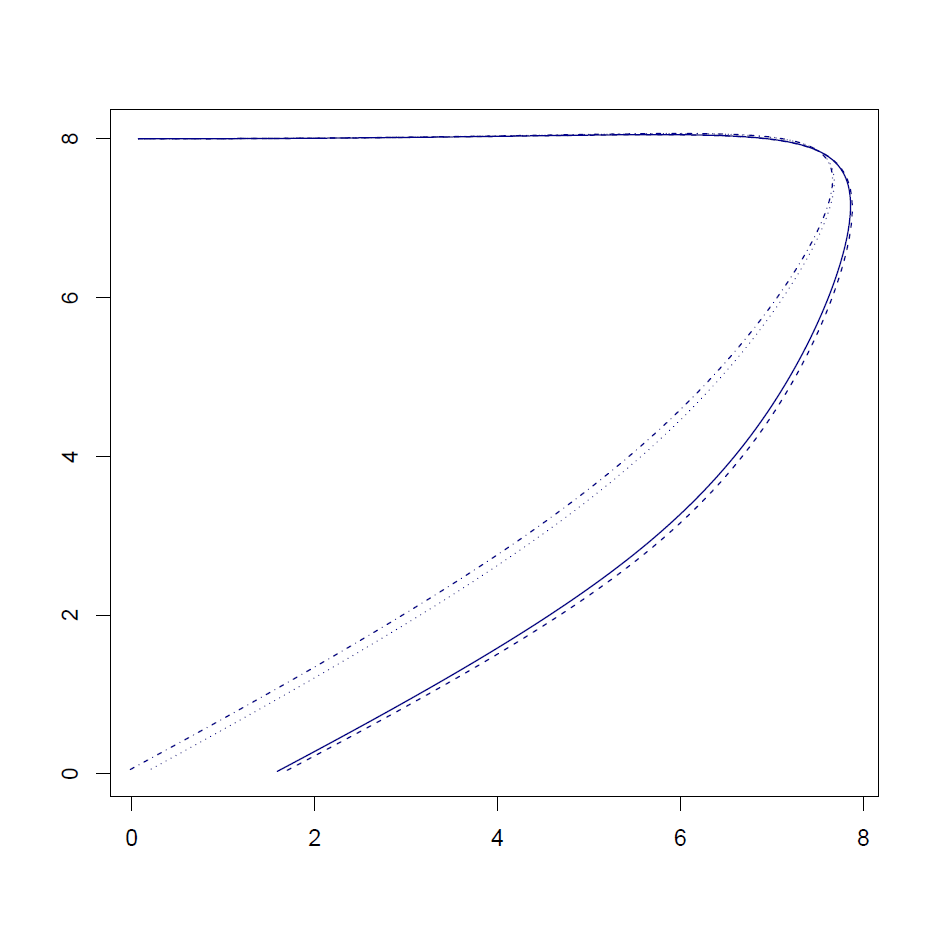
Consider a charged particle traveling in a plane with position \(\mathbf{x}(t)\), velocity \(\dot{\mathbf{x}}(t)\), initial position \(\mathbf{x}(0)=(0, 8)\), and initial velocity \(\dot{\mathbf{x}}(0)=(0.75, 0)\). The particle is accelerated by an electric field formed by a pair of repulsive bodies,
\[ p(\mathbf{x}; w) = \| \mathbf{x} - (10, 10 - w)\|^{-1} + \| \mathbf{x} - (10, 0)\|^{-1}\]
where \(w\) is a parameter of this simple particle simulation, adjusting the location of one of the repulsive bodies.
We can simulate the time evolution of this system by using a naive Euler ODE integration
\[ \begin{eqnarray*} \ddot{\mathbf{x}}(t) &=& \left. -\nabla_{\mathbf{x}} p(\mathbf{x}) \right|_{\mathbf{x}=\mathbf{x}(t)}\\ \dot{\mathbf{x}}(t + \Delta t) &=& \dot{\mathbf{x}}(t) + \Delta t \ddot{\mathbf{x}}(t)\\ \mathbf{x}(t + \Delta t) &=& \mathbf{x}(t) + \Delta t \dot{\mathbf{x}}(t) \end{eqnarray*}\]
where \(\Delta t\) is an integration time step.
For a given parameter \(w\), the simulation starts with \(t=0\) and finishes when the particle hits the \(x\)-axis, at position \(\mathbf{x}(t_f)\) at time \(t_f\). When the particle hits the \(x\)-axis, we calculate an error \(E(w) = x_0 (t_f)^2\), the squared horizontal distance of the particle from the origin. We then minimize this error using Newton's method, which finds the optimal value of \(w\) so that the particle eventually hits the \(x\)-axis at the origin.
\[ w^{(i+1)} = w^{(i)} - \frac{E'(w^{(i)})}{E''(w^{(i)})}\]
In other words, the code calculating the trajectory of the particle internally computes the gradient of the electric potential \(p(\mathbf{x}; w)\), and, at the same time, the final position of the trajectory \(\mathbf{x}(t_f)\) is used to compute an error, and the gradient and Hessian of this error are computed during the optimization procedure.
Here's how it goes.
1: 2: 3: 4: 5: 6: 7: 8: 9: 10: 11: 12: 13: 14: 15: 16: 17: 18: 19: 20: 21: 22: 23: 24: 25: 26: 27: 28: 29: |
|
[25/12/2015 23:53:10] --- Minimization started [25/12/2015 23:53:10] Parameters : 1 [25/12/2015 23:53:10] Iterations : 10 [25/12/2015 23:53:10] Valid. interval: 1 [25/12/2015 23:53:10] Method : Exact Newton [25/12/2015 23:53:10] Learning rate : Constant a = D 1.0f [25/12/2015 23:53:10] Momentum : None [25/12/2015 23:53:10] Gradient clip. : None [25/12/2015 23:53:10] Early stopping : None [25/12/2015 23:53:10] Improv. thresh.: D 0.995000005f [25/12/2015 23:53:10] Return best : true [25/12/2015 23:53:10] 1/10 | D 2.535113e+000 [- ] [25/12/2015 23:53:10] 2/10 | D 7.528733e-002 [↓▼] [25/12/2015 23:53:10] 3/10 | D 1.592970e-002 [↓▼] [25/12/2015 23:53:10] 4/10 | D 4.178338e-003 [↓▼] [25/12/2015 23:53:10] 5/10 | D 1.382800e-008 [↓▼] [25/12/2015 23:53:11] 6/10 | D 3.274181e-011 [↓▼] [25/12/2015 23:53:11] 7/10 | D 1.151079e-012 [↓▼] [25/12/2015 23:53:11] 8/10 | D 1.151079e-012 [- ] [25/12/2015 23:53:11] 9/10 | D 1.151079e-012 [- ] [25/12/2015 23:53:11] 10/10 | D 3.274181e-011 [↑ ] [25/12/2015 23:53:11] Duration : 00:00:00.9201285 [25/12/2015 23:53:11] Value initial : D 2.535113e+000 [25/12/2015 23:53:11] Value final : D 1.151079e-012 (Best) [25/12/2015 23:53:11] Value change : D -2.535113e+000 (-100.00 %) [25/12/2015 23:53:11] Value chg. / s : D -2.755173e+000 [25/12/2015 23:53:11] Iter. / s : 10.86804723 [25/12/2015 23:53:11] Iter. / min : 652.0828341 [25/12/2015 23:53:11] --- Minimization finishedval whist : DV [] = [|DV [|0.0f|]; DV [|0.20767726f|]; DV [|0.17457059f|]; DV [|0.190040559f|]; DV [|0.182180524f|]; DV [|0.182166189f|]; DV [|0.182166889f|]; DV [|0.182166755f|]; DV [|0.182166621f|]; DV [|0.182166487f|]|] val w : DV = DV [|0.182166889f|] val lhist : D [] = [|D 2.5351131f; D 2.5351131f; D 0.0752873272f; D 0.0159297027f; D 0.00417833822f; D 1.38279992e-08f; D 3.27418093e-11f; D 1.15107923e-12f; D 1.15107923e-12f; D 1.15107923e-12f|] val l : D = D 1.15107923e-12f
Optimization parameters
As another example, let's optimize the Beale function
\[ f(\mathbf{x}) = (1.5 - x_1 + x_1 x_2)^2 + (2.25 - x_1 + x_1 x_2^2)^2 + (2.625 - x_1 + x_1 x_2^3)^2\]
starting from \(\mathbf{x} = (1, 1.5)\), using RMSProp. The optimum is at \((3, 0.5)\)
1: 2: 3: 4: 5: 6: 7: 8: |
|
[12/11/2015 01:22:59] --- Minimization started [12/11/2015 01:22:59] Parameters : 2 [12/11/2015 01:22:59] Iterations : 3000 [12/11/2015 01:22:59] Valid. interval: 10 [12/11/2015 01:22:59] Method : Gradient descent [12/11/2015 01:22:59] Learning rate : RMSProp a0 = D 0.00999999978f, k = D 0.899999976f [12/11/2015 01:22:59] Momentum : None [12/11/2015 01:22:59] Gradient clip. : None [12/11/2015 01:22:59] Early stopping : None [12/11/2015 01:22:59] Improv. thresh.: D 0.995000005f [12/11/2015 01:22:59] Return best : true [12/11/2015 01:22:59] 1/3000 | D 4.125000e+001 [- ] [12/11/2015 01:22:59] 11/3000 | D 2.655878e+001 [↓▼] [12/11/2015 01:22:59] 21/3000 | D 2.154373e+001 [↓▼] [12/11/2015 01:22:59] 31/3000 | D 1.841705e+001 [↓▼] [12/11/2015 01:22:59] 41/3000 | D 1.624916e+001 [↓▼] [12/11/2015 01:22:59] 51/3000 | D 1.465973e+001 [↓▼] [12/11/2015 01:22:59] 61/3000 | D 1.334291e+001 [↓▼] ... [12/11/2015 01:22:59] 2921/3000 | D 9.084024e-004 [- ] [12/11/2015 01:22:59] 2931/3000 | D 9.084024e-004 [- ] [12/11/2015 01:22:59] 2941/3000 | D 9.084024e-004 [- ] [12/11/2015 01:22:59] 2951/3000 | D 9.084024e-004 [- ] [12/11/2015 01:22:59] 2961/3000 | D 9.084024e-004 [- ] [12/11/2015 01:22:59] 2971/3000 | D 9.084024e-004 [- ] [12/11/2015 01:22:59] 2981/3000 | D 9.084024e-004 [- ] [12/11/2015 01:22:59] 2991/3000 | D 9.084024e-004 [- ] [12/11/2015 01:22:59] Duration : 00:00:00.3142646 [12/11/2015 01:22:59] Value initial : D 4.125000e+001 [12/11/2015 01:22:59] Value final : D 8.948371e-004 (Best) [12/11/2015 01:22:59] Value change : D -4.124910e+001 (-100.00 %) [12/11/2015 01:22:59] Value chg. / s : D -1.312560e+002 [12/11/2015 01:22:59] Iter. / s : 9546.09587 [12/11/2015 01:22:59] Iter. / min : 572765.7522 [12/11/2015 01:22:59] --- Minimization finishedval wopt : DV = DV [|2.99909306f; 0.50039643f|]
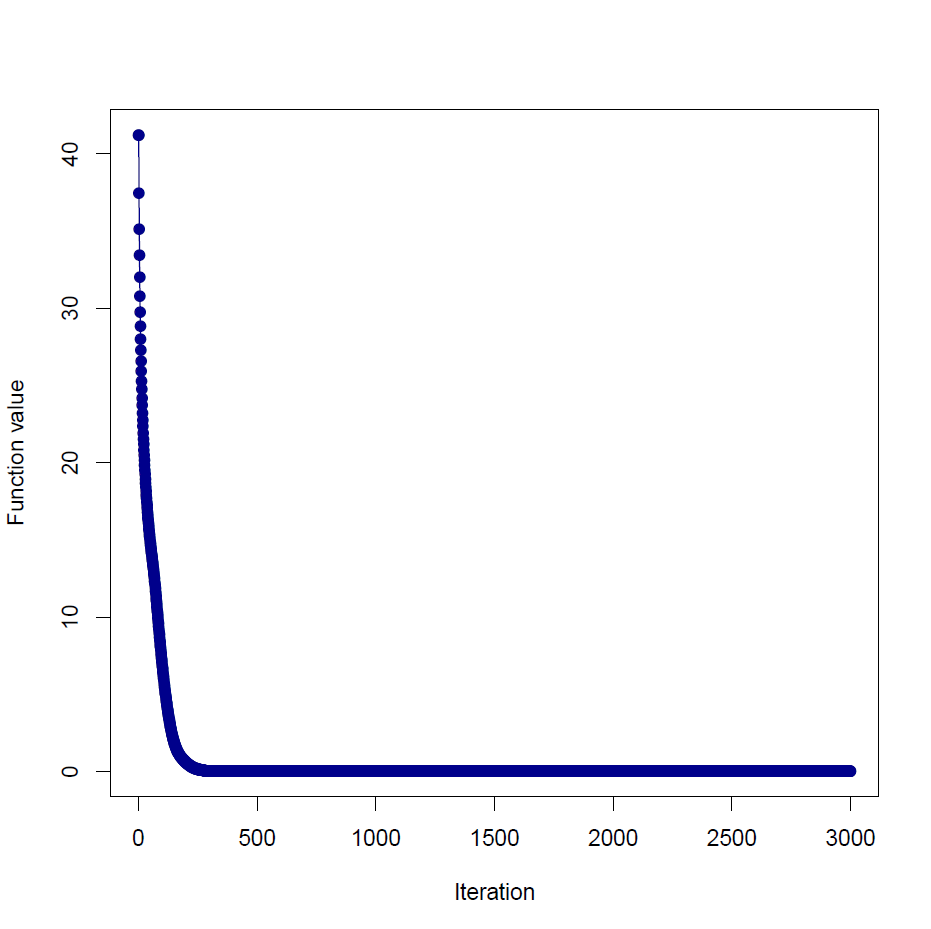
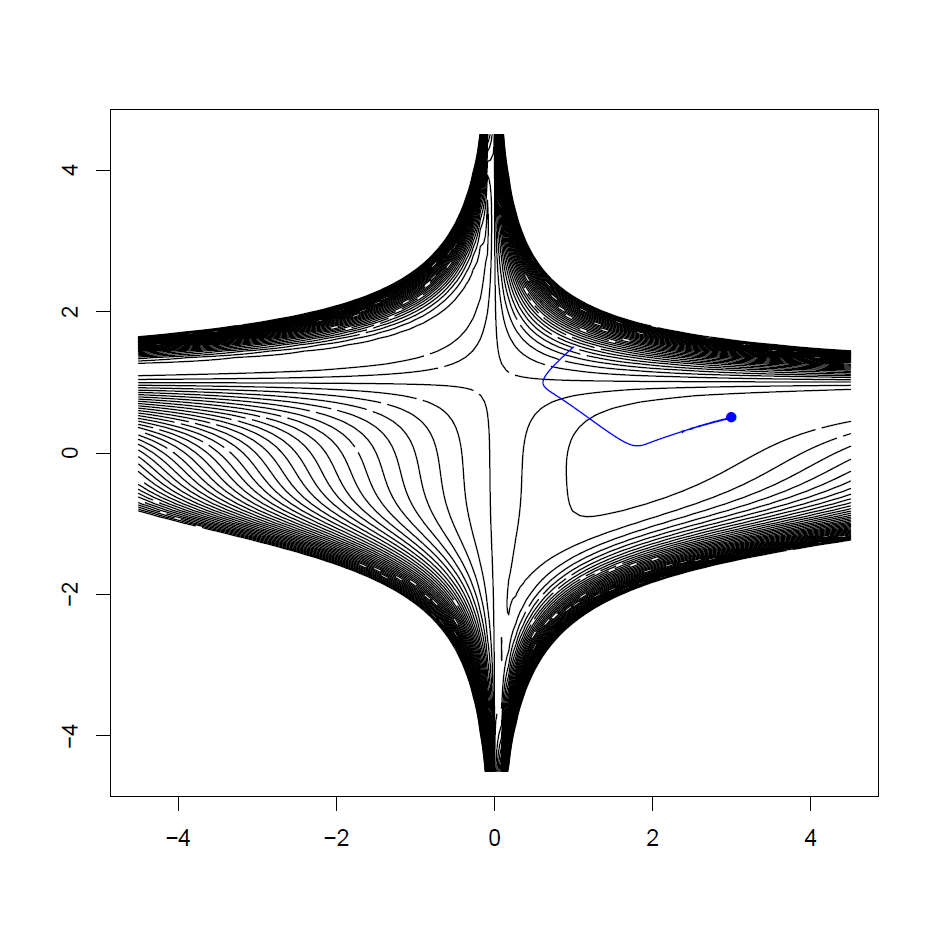
Each instantiation of gradient-based optimization is controlled through a collection of parameters, using the Hype.Params type.
If you do not supply any parameters to optimization, the default parameter set Params.Default is used. The default parameters look like this:
1: 2: 3: 4: 5: 6: 7: 8: 9: 10: 11: 12: 13: 14: 15: |
|
If you want to change only a specific element of the parameter type, you can do so by extending the Params.Default value and overwriting only the parts you need to change, such as this:
1: 2: 3: 4: |
|
Optimization method
1: 2: 3: 4: 5: 6: 7: 8: |
|
Learning rate
1: 2: 3: 4: 5: 6: 7: 8: 9: 10: 11: 12: 13: 14: 15: 16: |
|
Momentum
1: 2: 3: 4: 5: 6: |
|
Gradient clipping
1: 2: 3: 4: |
|
Finally, looking at the API reference and the source code of the optimization module can give you a better idea of the optimization algorithms currently implemented.
from DiffSharp.AD
Full name: Optimization.dt
Full name: Optimization.x0
Full name: DiffSharp.AD.Float32.DOps.toDV
Full name: Optimization.v0
Full name: Optimization.p
union case DV.DV: float32 [] -> DV
--------------------
module DV
from DiffSharp.AD.Float32
--------------------
type DV =
| DV of float32 []
| DVF of DV * DV * uint32
| DVR of DV * DV ref * TraceOp * uint32 ref * uint32
member Copy : unit -> DV
member GetForward : t:DV * i:uint32 -> DV
member GetReverse : i:uint32 -> DV
member GetSlice : lower:int option * upper:int option -> DV
member ToArray : unit -> D []
member ToColDM : unit -> DM
member ToMathematicaString : unit -> string
member ToMatlabString : unit -> string
member ToRowDM : unit -> DM
override ToString : unit -> string
member Visualize : unit -> string
member A : DV
member F : uint32
member Item : i:int -> D with get
member Length : int
member P : DV
member PD : DV
member T : DV
member A : DV with set
member F : uint32 with set
static member Abs : a:DV -> DV
static member Acos : a:DV -> DV
static member AddItem : a:DV * i:int * b:D -> DV
static member AddSubVector : a:DV * i:int * b:DV -> DV
static member Append : a:DV * b:DV -> DV
static member Asin : a:DV -> DV
static member Atan : a:DV -> DV
static member Atan2 : a:int * b:DV -> DV
static member Atan2 : a:DV * b:int -> DV
static member Atan2 : a:float32 * b:DV -> DV
static member Atan2 : a:DV * b:float32 -> DV
static member Atan2 : a:D * b:DV -> DV
static member Atan2 : a:DV * b:D -> DV
static member Atan2 : a:DV * b:DV -> DV
static member Ceiling : a:DV -> DV
static member Cos : a:DV -> DV
static member Cosh : a:DV -> DV
static member Exp : a:DV -> DV
static member Floor : a:DV -> DV
static member L1Norm : a:DV -> D
static member L2Norm : a:DV -> D
static member L2NormSq : a:DV -> D
static member Log : a:DV -> DV
static member Log10 : a:DV -> DV
static member LogSumExp : a:DV -> D
static member Max : a:DV -> D
static member Max : a:D * b:DV -> DV
static member Max : a:DV * b:D -> DV
static member Max : a:DV * b:DV -> DV
static member MaxIndex : a:DV -> int
static member Mean : a:DV -> D
static member Min : a:DV -> D
static member Min : a:D * b:DV -> DV
static member Min : a:DV * b:D -> DV
static member Min : a:DV * b:DV -> DV
static member MinIndex : a:DV -> int
static member Normalize : a:DV -> DV
static member OfArray : a:D [] -> DV
static member Op_DV_D : a:DV * ff:(float32 [] -> float32) * fd:(DV -> D) * df:(D * DV * DV -> D) * r:(DV -> TraceOp) -> D
static member Op_DV_DM : a:DV * ff:(float32 [] -> float32 [,]) * fd:(DV -> DM) * df:(DM * DV * DV -> DM) * r:(DV -> TraceOp) -> DM
static member Op_DV_DV : a:DV * ff:(float32 [] -> float32 []) * fd:(DV -> DV) * df:(DV * DV * DV -> DV) * r:(DV -> TraceOp) -> DV
static member Op_DV_DV_D : a:DV * b:DV * ff:(float32 [] * float32 [] -> float32) * fd:(DV * DV -> D) * df_da:(D * DV * DV -> D) * df_db:(D * DV * DV -> D) * df_dab:(D * DV * DV * DV * DV -> D) * r_d_d:(DV * DV -> TraceOp) * r_d_c:(DV * DV -> TraceOp) * r_c_d:(DV * DV -> TraceOp) -> D
static member Op_DV_DV_DM : a:DV * b:DV * ff:(float32 [] * float32 [] -> float32 [,]) * fd:(DV * DV -> DM) * df_da:(DM * DV * DV -> DM) * df_db:(DM * DV * DV -> DM) * df_dab:(DM * DV * DV * DV * DV -> DM) * r_d_d:(DV * DV -> TraceOp) * r_d_c:(DV * DV -> TraceOp) * r_c_d:(DV * DV -> TraceOp) -> DM
static member Op_DV_DV_DV : a:DV * b:DV * ff:(float32 [] * float32 [] -> float32 []) * fd:(DV * DV -> DV) * df_da:(DV * DV * DV -> DV) * df_db:(DV * DV * DV -> DV) * df_dab:(DV * DV * DV * DV * DV -> DV) * r_d_d:(DV * DV -> TraceOp) * r_d_c:(DV * DV -> TraceOp) * r_c_d:(DV * DV -> TraceOp) -> DV
static member Op_DV_D_DV : a:DV * b:D * ff:(float32 [] * float32 -> float32 []) * fd:(DV * D -> DV) * df_da:(DV * DV * DV -> DV) * df_db:(DV * D * D -> DV) * df_dab:(DV * DV * DV * D * D -> DV) * r_d_d:(DV * D -> TraceOp) * r_d_c:(DV * D -> TraceOp) * r_c_d:(DV * D -> TraceOp) -> DV
static member Op_D_DV_DV : a:D * b:DV * ff:(float32 * float32 [] -> float32 []) * fd:(D * DV -> DV) * df_da:(DV * D * D -> DV) * df_db:(DV * DV * DV -> DV) * df_dab:(DV * D * D * DV * DV -> DV) * r_d_d:(D * DV -> TraceOp) * r_d_c:(D * DV -> TraceOp) * r_c_d:(D * DV -> TraceOp) -> DV
static member Pow : a:int * b:DV -> DV
static member Pow : a:DV * b:int -> DV
static member Pow : a:float32 * b:DV -> DV
static member Pow : a:DV * b:float32 -> DV
static member Pow : a:D * b:DV -> DV
static member Pow : a:DV * b:D -> DV
static member Pow : a:DV * b:DV -> DV
static member ReLU : a:DV -> DV
static member ReshapeToDM : m:int * a:DV -> DM
static member Round : a:DV -> DV
static member Sigmoid : a:DV -> DV
static member Sign : a:DV -> DV
static member Sin : a:DV -> DV
static member Sinh : a:DV -> DV
static member SoftMax : a:DV -> DV
static member SoftPlus : a:DV -> DV
static member SoftSign : a:DV -> DV
static member Split : d:DV * n:seq<int> -> seq<DV>
static member Sqrt : a:DV -> DV
static member StandardDev : a:DV -> D
static member Standardize : a:DV -> DV
static member Sum : a:DV -> D
static member Tan : a:DV -> DV
static member Tanh : a:DV -> DV
static member Variance : a:DV -> D
static member ZeroN : n:int -> DV
static member Zero : DV
static member ( + ) : a:int * b:DV -> DV
static member ( + ) : a:DV * b:int -> DV
static member ( + ) : a:float32 * b:DV -> DV
static member ( + ) : a:DV * b:float32 -> DV
static member ( + ) : a:D * b:DV -> DV
static member ( + ) : a:DV * b:D -> DV
static member ( + ) : a:DV * b:DV -> DV
static member ( &* ) : a:DV * b:DV -> DM
static member ( / ) : a:int * b:DV -> DV
static member ( / ) : a:DV * b:int -> DV
static member ( / ) : a:float32 * b:DV -> DV
static member ( / ) : a:DV * b:float32 -> DV
static member ( / ) : a:D * b:DV -> DV
static member ( / ) : a:DV * b:D -> DV
static member ( ./ ) : a:DV * b:DV -> DV
static member ( .* ) : a:DV * b:DV -> DV
static member op_Explicit : d:float32 [] -> DV
static member op_Explicit : d:DV -> float32 []
static member ( * ) : a:int * b:DV -> DV
static member ( * ) : a:DV * b:int -> DV
static member ( * ) : a:float32 * b:DV -> DV
static member ( * ) : a:DV * b:float32 -> DV
static member ( * ) : a:D * b:DV -> DV
static member ( * ) : a:DV * b:D -> DV
static member ( * ) : a:DV * b:DV -> D
static member ( - ) : a:int * b:DV -> DV
static member ( - ) : a:DV * b:int -> DV
static member ( - ) : a:float32 * b:DV -> DV
static member ( - ) : a:DV * b:float32 -> DV
static member ( - ) : a:D * b:DV -> DV
static member ( - ) : a:DV * b:D -> DV
static member ( - ) : a:DV * b:DV -> DV
static member ( ~- ) : a:DV -> DV
Full name: DiffSharp.AD.Float32.DV
Full name: DiffSharp.AD.Float32.DV.norm
Full name: Optimization.trajectory
| D of float32
| DF of D * D * uint32
| DR of D * D ref * TraceOp * uint32 ref * uint32
interface IComparable
member Copy : unit -> D
override Equals : other:obj -> bool
member GetForward : t:D * i:uint32 -> D
override GetHashCode : unit -> int
member GetReverse : i:uint32 -> D
override ToString : unit -> string
member A : D
member F : uint32
member P : D
member PD : D
member T : D
member A : D with set
member F : uint32 with set
static member Abs : a:D -> D
static member Acos : a:D -> D
static member Asin : a:D -> D
static member Atan : a:D -> D
static member Atan2 : a:int * b:D -> D
static member Atan2 : a:D * b:int -> D
static member Atan2 : a:float32 * b:D -> D
static member Atan2 : a:D * b:float32 -> D
static member Atan2 : a:D * b:D -> D
static member Ceiling : a:D -> D
static member Cos : a:D -> D
static member Cosh : a:D -> D
static member Exp : a:D -> D
static member Floor : a:D -> D
static member Log : a:D -> D
static member Log10 : a:D -> D
static member LogSumExp : a:D -> D
static member Max : a:D * b:D -> D
static member Min : a:D * b:D -> D
static member Op_D_D : a:D * ff:(float32 -> float32) * fd:(D -> D) * df:(D * D * D -> D) * r:(D -> TraceOp) -> D
static member Op_D_D_D : a:D * b:D * ff:(float32 * float32 -> float32) * fd:(D * D -> D) * df_da:(D * D * D -> D) * df_db:(D * D * D -> D) * df_dab:(D * D * D * D * D -> D) * r_d_d:(D * D -> TraceOp) * r_d_c:(D * D -> TraceOp) * r_c_d:(D * D -> TraceOp) -> D
static member Pow : a:int * b:D -> D
static member Pow : a:D * b:int -> D
static member Pow : a:float32 * b:D -> D
static member Pow : a:D * b:float32 -> D
static member Pow : a:D * b:D -> D
static member ReLU : a:D -> D
static member Round : a:D -> D
static member Sigmoid : a:D -> D
static member Sign : a:D -> D
static member Sin : a:D -> D
static member Sinh : a:D -> D
static member SoftPlus : a:D -> D
static member SoftSign : a:D -> D
static member Sqrt : a:D -> D
static member Tan : a:D -> D
static member Tanh : a:D -> D
static member One : D
static member Zero : D
static member ( + ) : a:int * b:D -> D
static member ( + ) : a:D * b:int -> D
static member ( + ) : a:float32 * b:D -> D
static member ( + ) : a:D * b:float32 -> D
static member ( + ) : a:D * b:D -> D
static member ( / ) : a:int * b:D -> D
static member ( / ) : a:D * b:int -> D
static member ( / ) : a:float32 * b:D -> D
static member ( / ) : a:D * b:float32 -> D
static member ( / ) : a:D * b:D -> D
static member op_Explicit : d:D -> float32
static member ( * ) : a:int * b:D -> D
static member ( * ) : a:D * b:int -> D
static member ( * ) : a:float32 * b:D -> D
static member ( * ) : a:D * b:float32 -> D
static member ( * ) : a:D * b:D -> D
static member ( - ) : a:int * b:D -> D
static member ( - ) : a:D * b:int -> D
static member ( - ) : a:float32 * b:D -> D
static member ( - ) : a:D * b:float32 -> D
static member ( - ) : a:D * b:D -> D
static member ( ~- ) : a:D -> D
Full name: DiffSharp.AD.Float32.D
from Microsoft.FSharp.Collections
Full name: Microsoft.FSharp.Collections.Seq.unfold
Full name: DiffSharp.AD.Float32.DiffOps.grad
Full name: Microsoft.FSharp.Collections.Seq.takeWhile
Full name: Optimization.error
Full name: Microsoft.FSharp.Collections.Seq.last
Full name: Optimization.w
Full name: Optimization.l
Full name: Optimization.whist
Full name: Optimization.lhist
static member Minimize : f:(DV -> D) * w0:DV -> DV * D * DV [] * D []
static member Minimize : f:(DV -> D) * w0:DV * par:Params -> DV * D * DV [] * D []
static member Train : f:(DV -> DM -> DM) * w0:DV * d:Dataset -> DV * D * DV [] * D []
static member Train : f:(DV -> DV -> DV) * w0:DV * d:Dataset -> DV * D * DV [] * D []
static member Train : f:(DV -> DV -> D) * w0:DV * d:Dataset -> DV * D * DV [] * D []
static member Train : f:(DV -> DM -> DM) * w0:DV * d:Dataset * v:Dataset -> DV * D * DV [] * D []
static member Train : f:(DV -> DM -> DM) * w0:DV * d:Dataset * par:Params -> DV * D * DV [] * D []
static member Train : f:(DV -> DV -> DV) * w0:DV * d:Dataset * v:Dataset -> DV * D * DV [] * D []
static member Train : f:(DV -> DV -> DV) * w0:DV * d:Dataset * par:Params -> DV * D * DV [] * D []
static member Train : f:(DV -> DV -> D) * w0:DV * d:Dataset * v:Dataset -> DV * D * DV [] * D []
...
Full name: Hype.Optimize
static member Optimize.Minimize : f:(DV -> D) * w0:DV * par:Params -> DV * D * DV [] * D []
module Params
from Hype
--------------------
type Params =
{Epochs: int;
Method: Method;
LearningRate: LearningRate;
Momentum: Momentum;
Loss: Loss;
Regularization: Regularization;
GradientClipping: GradientClipping;
Batch: Batch;
EarlyStopping: EarlyStopping;
ImprovementThreshold: D;
...}
Full name: Hype.Params
Full name: Hype.Params.Default
| GD
| CG
| CD
| NonlinearCG
| DaiYuanCG
| NewtonCG
| Newton
override ToString : unit -> string
member Func : (DV -> (DV -> D) -> DV -> DV -> (DV -> DV) -> D * DV * DV)
Full name: Hype.Method
| Constant of D
| Decay of D * D
| ExpDecay of D * D
| Schedule of DV
| Backtrack of D * D * D
| StrongWolfe of D * D * D
| AdaGrad of D
| RMSProp of D * D
override ToString : unit -> string
member Func : (int -> DV -> (DV -> D) -> D -> DV -> DV ref -> DV -> obj)
static member DefaultAdaGrad : LearningRate
static member DefaultBacktrack : LearningRate
static member DefaultConstant : LearningRate
static member DefaultDecay : LearningRate
static member DefaultExpDecay : LearningRate
static member DefaultRMSProp : LearningRate
static member DefaultStrongWolfe : LearningRate
Full name: Hype.LearningRate
static member Axis : ?x: obj * ?at: obj * ?___: obj * ?side: obj * ?labels: obj * ?paramArray: obj [] -> SymbolicExpression + 1 overload
static member abline : ?a: obj * ?b: obj * ?h: obj * ?v: obj * ?reg: obj * ?coef: obj * ?untf: obj * ?___: obj * ?paramArray: obj [] -> SymbolicExpression + 1 overload
static member arrows : ?x0: obj * ?y0: obj * ?x1: obj * ?y1: obj * ?length: obj * ?angle: obj * ?code: obj * ?col: obj * ?lty: obj * ?lwd: obj * ?___: obj * ?paramArray: obj [] -> SymbolicExpression + 1 overload
static member assocplot : ?x: obj * ?col: obj * ?space: obj * ?main: obj * ?xlab: obj * ?ylab: obj -> SymbolicExpression + 1 overload
static member axTicks : ?side: obj * ?axp: obj * ?usr: obj * ?log: obj * ?nintLog: obj -> SymbolicExpression + 1 overload
static member axis : ?side: obj * ?at: obj * ?labels: obj * ?tick: obj * ?line: obj * ?pos: obj * ?outer: obj * ?font: obj * ?lty: obj * ?lwd: obj * ?lwd_ticks: obj * ?col: obj * ?col_ticks: obj * ?hadj: obj * ?padj: obj * ?___: obj * ?paramArray: obj [] -> SymbolicExpression + 1 overload
static member axis_Date : ?side: obj * ?x: obj * ?at: obj * ?format: obj * ?labels: obj * ?___: obj * ?paramArray: obj [] -> SymbolicExpression + 1 overload
static member axis_POSIXct : ?side: obj * ?x: obj * ?at: obj * ?format: obj * ?labels: obj * ?___: obj * ?paramArray: obj [] -> SymbolicExpression + 1 overload
static member barplot : ?height: obj * ?___: obj * ?paramArray: obj [] -> SymbolicExpression + 1 overload
static member barplot_default : ?height: obj * ?width: obj * ?space: obj * ?names_arg: obj * ?legend_text: obj * ?beside: obj * ?horiz: obj * ?density: obj * ?angle: obj * ?col: obj * ?border: obj * ?main: obj * ?sub: obj * ?xlab: obj * ?ylab: obj * ?xlim: obj * ?ylim: obj * ?xpd: obj * ?log: obj * ?axes: obj * ?axisnames: obj * ?cex_axis: obj * ?cex_names: obj * ?inside: obj * ?plot: obj * ?axis_lty: obj * ?offset: obj * ?add: obj * ?args_legend: obj * ?___: obj * ?paramArray: obj [] -> SymbolicExpression + 1 overload
...
Full name: RProvider.graphics.R
R functions for base graphics
R.plot_new(?NULL: obj) : RDotNet.SymbolicExpression
No documentation available
Full name: RProvider.Helpers.namedParams
Full name: Optimization.t
Full name: Optimization.tx
Full name: Optimization.ty
Full name: Microsoft.FSharp.Collections.Seq.toArray
from Microsoft.FSharp.Collections
Full name: Microsoft.FSharp.Collections.Array.map
val float32 : value:'T -> float32 (requires member op_Explicit)
Full name: Microsoft.FSharp.Core.Operators.float32
--------------------
type float32 = System.Single
Full name: Microsoft.FSharp.Core.float32
--------------------
type float32<'Measure> = float32
Full name: Microsoft.FSharp.Core.float32<_>
val float : value:'T -> float (requires member op_Explicit)
Full name: Microsoft.FSharp.Core.Operators.float
--------------------
type float = System.Double
Full name: Microsoft.FSharp.Core.float
--------------------
type float<'Measure> = float
Full name: Microsoft.FSharp.Core.float<_>
Full name: Microsoft.FSharp.Collections.Array.unzip
Full name: Microsoft.FSharp.Core.Operators.box
R.lines(?x: obj, ?___: obj, ?paramArray: obj []) : RDotNet.SymbolicExpression
Add Connected Line Segments to a Plot
Full name: Microsoft.FSharp.Core.Operators.ignore
Full name: Optimization.beale
Full name: Optimization.wopt
Full name: Optimization.lopt
Full name: Optimization.ll
R.plot(?x: obj, ?y: obj, ?___: obj, ?paramArray: obj []) : RDotNet.SymbolicExpression
Generic X-Y Plotting
Full name: Optimization.contourplot3d
from Microsoft.FSharp.Collections
Full name: Microsoft.FSharp.Collections.Array2D.init
Full name: Microsoft.FSharp.Collections.Array2D.map
R.contour(?x: obj, ?___: obj, ?paramArray: obj []) : RDotNet.SymbolicExpression
Display Contours
Full name: Optimization.xx
Full name: Optimization.yy
Full name: Microsoft.FSharp.Collections.Array.last
R.points(?x: obj, ?___: obj, ?paramArray: obj []) : RDotNet.SymbolicExpression
Add Points to a Plot
Full name: Optimization.Params.Default
union case Momentum.Momentum: D -> Momentum
--------------------
type Momentum =
| Momentum of D
| Nesterov of D
| NoMomentum
override ToString : unit -> string
member Func : (DV -> DV -> DV)
static member DefaultMomentum : Momentum
static member DefaultNesterov : Momentum
Full name: Hype.Momentum
| L1Loss
| L2Loss
| Quadratic
| CrossEntropyOnLinear
| CrossEntropyOnSoftmax
override ToString : unit -> string
member Func : (Dataset -> (DM -> DM) -> D)
Full name: Hype.Loss
| L1Reg of D
| L2Reg of D
| NoReg
override ToString : unit -> string
member Func : (DV -> D)
static member DefaultL1Reg : Regularization
static member DefaultL2Reg : Regularization
Full name: Hype.Regularization
| NormClip of D
| NoClip
override ToString : unit -> string
member Func : (DV -> DV)
static member DefaultNormClip : GradientClipping
Full name: Hype.GradientClipping
| Full
| Minibatch of int
| Stochastic
override ToString : unit -> string
member Func : (Dataset -> int -> Dataset)
Full name: Hype.Batch
| Early of int * int
| NoEarly
override ToString : unit -> string
static member DefaultEarly : EarlyStopping
Full name: Hype.EarlyStopping
Full name: Optimization.p
module Params
from Optimization
--------------------
module Params
from Hype
--------------------
type Params =
{Epochs: int;
Method: Method;
LearningRate: LearningRate;
Momentum: Momentum;
Loss: Loss;
Regularization: Regularization;
GradientClipping: GradientClipping;
Batch: Batch;
EarlyStopping: EarlyStopping;
ImprovementThreshold: D;
...}
Full name: Hype.Params
val Default : Params
Full name: Optimization.Params.Default
--------------------
val Default : Params
Full name: Hype.Params.Default
| GD
| CG
| CD
| NonlinearCG
| DaiYuanCG
| NewtonCG
| Newton
Full name: Optimization.Method
| Constant of D
| Decay of D * D
| ExpDecay of D * D
| Schedule of DV
| Backtrack of D * D * D
| StrongWolfe of D * D * D
| AdaGrad of D
| RMSProp of D * D
static member DefaultAdaGrad : LearningRate
static member DefaultBacktrack : LearningRate
static member DefaultConstant : LearningRate
static member DefaultDecay : LearningRate
static member DefaultExpDecay : LearningRate
static member DefaultRMSProp : LearningRate
static member DefaultStrongWolfe : LearningRate
Full name: Optimization.LearningRate
Full name: Optimization.LearningRate.DefaultConstant
Full name: Optimization.LearningRate.DefaultDecay
Full name: Optimization.LearningRate.DefaultExpDecay
Full name: Optimization.LearningRate.DefaultBacktrack
Full name: Optimization.LearningRate.DefaultStrongWolfe
Full name: Optimization.LearningRate.DefaultAdaGrad
Full name: Optimization.LearningRate.DefaultRMSProp
union case Momentum.Momentum: D -> Momentum
--------------------
type Momentum =
| Momentum of D
| Nesterov of D
| NoMomentum
static member DefaultMomentum : Momentum
static member DefaultNesterov : Momentum
Full name: Optimization.Momentum
Full name: Optimization.Momentum.DefaultMomentum
Full name: Optimization.Momentum.DefaultNesterov
| NormClip of D
| NoClip
static member DefaultNormClip : GradientClipping
Full name: Optimization.GradientClipping
Full name: Optimization.GradientClipping.DefaultNormClip
